

Filtering the firehose
Finding relevant content from the web for every user


It's hard to overstate how much recent developments have changed what's possible for a small team, like ours at Continua, to do in a small amount of time. There’s a common saying that 20% of the work will get you 80% of the way there. In the last few years, LLMs have pushed that 20% down even lower. That's especially true in cases where real customer usage data would have been needed to start spinning up a machine learning based pipeline. This was definitely our experience while building out a system for selecting web content based on a user provided podcast description. For example, if a user tells us “I want to hear about AI startups in New York”, how can we efficiently find a set of recent webpages which match that interest? To solve this type of problem in the recent past, you'd need either a large amount of user behavior data, or expensive manually annotated data to build such a system, but as we'll describe below, you can now build a very capable system without needing either of those.
In our last post, we discussed how we crawl the web to find a large amount of interesting content. In this post, we'll explain how we were able to quickly build out a content filtering system which is both efficient and high quality. Why not just use a search engine, or an LLM provider like Perplexity? The easiest answer is price, but more importantly, traditional search wouldn’t cut it for this use case, or other agentic applications we build. To deliver the highest quality results, we think it’s essential to own the whole process from data cleaning, to indexing, to retrieval.
High recall first, High precision last
The standard approach for efficiently processing a large amount of data is to use a tiered system, where content passes through a series of successive filters, with each stage becoming more expensive and selective.1 With an infinite budget, we could just pass our entire stream of web content through a high quality model once for each candidate podcast, but that would be far too expensive. Instead, the approach is to pass the data through a series of filters, where the earlier ones prioritize recall (i.e. low false negative rate), and the later ones increasingly prioritize precision (i.e. low false positive rate).
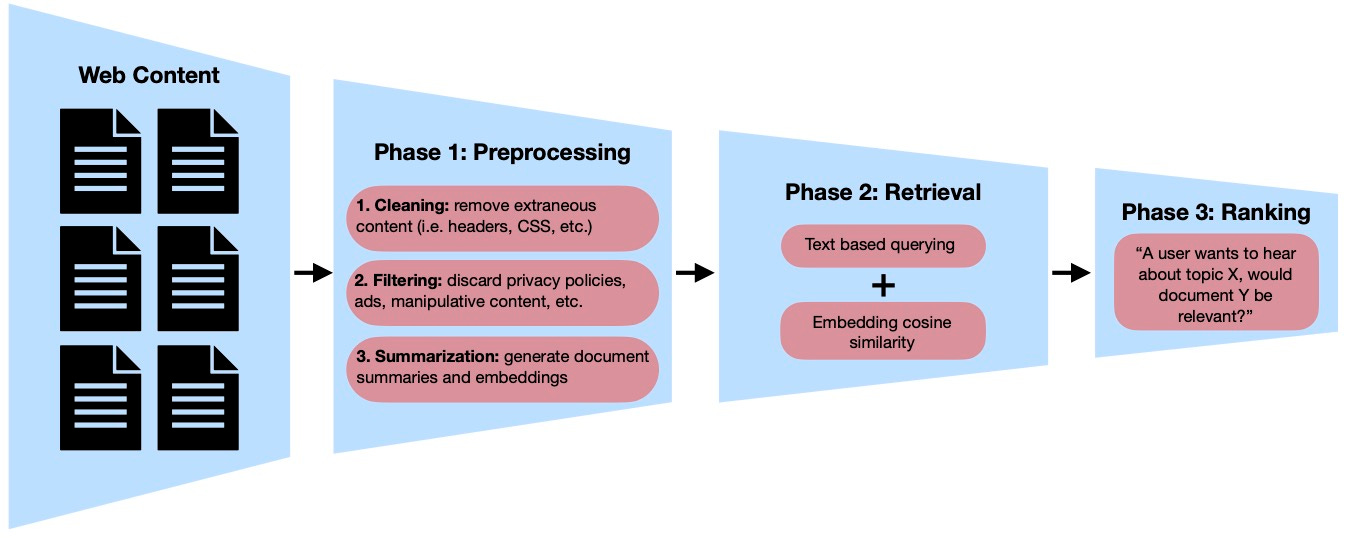
Phase 1: Preprocessing
The first stage of our pipeline handles the basic processing needed for all the web content we ingest. Anything that will be needed for all future queries is computed at this stage, to avoid needlessly recomputing things in the future. The goal of this stage is to convert and filter raw web content to give us an optimized starting point for our search for relevant content.
Cleaning
Before we get to running any ML-based solutions on a webpage, we want to do our best to minimize the representation of that page. For example, for a blog post, there might be a header, footer, tons of CSS, javascript and so on in the HTML. Anything which isn't semantic which we fail to filter out at this point becomes a recurring cost at every future stage of the pipeline.
We use a few rule based methods which cover almost all web pages, and fall back to using an LLM to extract the page text in a small number of cases. The ideal output is a version of the document which contains all the useful information and as little excess as possible. There are even benefits to the downstream quality, since some work has shown that increasing the input length to LLMs can degrade their performance, even when the task is unchanged.
Filtering
Next, we want to remove documents which won't be of interest to any user. There are a lot of things on the web which, as far as a user looking for interesting information is concerned, are just junk. This junk includes (but definitely isn't limited to): Privacy policies, sign-up pages, shop pages, and many kinds of manipulative content. One particularly interesting example was a “news” website which plagiarized articles from other sources, and avoided detection by swapping words for synonyms. We use GPT-4o-mini to filter out as many of these as possible, reducing load and noise in every subsequent stage of the pipeline.
Summarization
Once we've minimized the text and thrown out the "junk", we compute features which will be used for retrieval in the future. The first of these are abstractive and extractive summaries, computed with GPT-4o-mini. By total expenditure, this step is the most expensive part of the pipeline, but using summaries instead of full-text for future stages allows us to avoid using the full document in later stages. This step is also a part of our pipeline that we'll be looking to substitute self-hosted models for early on, as we scale up.
Having computed the summary, we also compute an embedding of each summary for use in retrieval. The main benefit is that we don't need to worry about any issues which arise from pages longer than the maximum context of our embedding model. Another, less obvious, benefit is that similar style across different summaries means there won't be as many surface-level differences affecting embedding similarity search. For example, all else equal, one should expect a Markdown document to embed closer to another Markdown document than it would to an HTML document. We want to avoid that sort of bias in our retrieval, and focus purely on the content.
Second stage: Retrieval
The summaries and embeddings from the pre-processing phase form the data source we use to build all of our podcasts. For each podcast episode, we periodically query for new relevant content over the course of each day. This retrieval process is tuned to be high recall, as we're willing to catch a large number of false positives in order to avoid a single false negative. We use a combination of cosine similarity, and BM25.
Rather than making just a single query, we first query on a per-site basis, using both sites users have manually requested, and ones that we predict will be relevant based on their podcast description, and the historical data for those sites. To avoid missing out on potentially relevant content, we also make a query across our entire set of ingested pages for the day, increasing the odds that we find relevant topics to cover.
Third stage: Ranking
At this point, for each user's podcast, we have access to a much smaller set of possible candidate documents. For each one, we need to answer the question: "A user wants to hear about topic X, would document Y be relevant?". This stage is the one which looks the most different from how it might have looked a few years ago. The earlier stages (cleaning, filtering, retrieval) might all be possible using rule-based heuristics or off-the-shelf models, but this stage would require a custom trained model. Now, it's possible to get good results without training, but as we found, fine-tuning still offers major advantages in both accuracy and cost.
Version 1: Few-shot
To start with, we used Gemini 1.5 Flash with a few-shot prompt. This approach struck a good initial balance of price to quality, especially after some tuning of the prompt, but didn't meet our quality bar. One example I ran into early in testing was asking for a podcast about AI for genomics, for which the ranking model gave me way too many pages about just AI or just genomics. In testing, this behavior was improved significantly by using models like Gemini Pro or Claude 3.5 Sonnet, but those models were too expensive for this use case.
Even the SotA models weren't good enough, as they kept getting a lot of edge cases wrong. We found that even when we tried many prompt variations to avoid these cases, the models weren't following all the instructions simultaneously. At the end of the day, it is extremely hard (or maybe impossible) to encode exactly the behavior you want within a few thousand tokens of text. As a result, we decided to switch to fine-tuned models, in order to solve both the quality and cost problems simultaneously.
Version 2: Fine-tuned

To improve our ranking while keeping costs down, we turned to model distillation. We used the Gemini Flash fine-tuning API to distill results from Claude Sonnet models2. Distillation is probably best thought of as throwing out the parts of a big model you don't want to pay for. All we care about is Claude's ability to evaluate the relevance of web documents, not its coding capabilities or (not amazing) sense of humor. By generating data using Claude and fine-tuning Gemini Flash on said data, we can achieve much better results than we'd get by using Gemini Flash directly.
To generate data, we used a three step approach. First, we hand-wrote a small (< 20) number of podcast descriptions which are similar to the types of inputs we expect from users. Next, we used Claude to generate a large number of additional possible user queries. Finally, these inputs were used as the basis for creating a distillation set.
In order to get high quality distillation data, we used the best available (at the time) model, Claude 3.5 Sonnet. We used it to evaluate a large number of candidate web pages for relevance against the synthetic user inputs we produced in the previous step. However, even using the best model wasn’t enough, since we found certain classes of errors which we could prevent Claude from making (despite a large amount of prompt tweaking).
While we couldn’t get Claude to behave reliably in the context of a single call, it was able to notice that it made a mistake of a given type if it was specifically re-prompted to evaluate its answer and check whether that kind of mistake was present. While that approach would effectively double our costs if used in production, doubling the cost of producing a distillation set is a one-time cost, and well worth it.
For example, we found that if asked to rate content about “News about AI, or startups”, Claude would often only rate content highly if it was about both topics. By adding an explicit double check for this “union of topics” case, we were able to significantly reduce the false negative rate in our distillation set.
Wrapping up
The final product is a podcast which has just what the user asked for. For example, here’s the intro to my “Seattle update”, which gives me daily news for my neighborhood, and other specific topics I’m interested in:

And here are the pages that our system selected to generate that episode:

Our pipeline marries traditional information retrieval techniques with modern language models to create an efficient filtering system. It begins with filtering and cleaning of web data, moves into an embedding and retrieval stage designed to prioritize high recall over high precision, and finishes with a filtering process powered by relatively inexpensive yet finely tuned models that address our unique use case. The cost and speed at which we built this system would have been unimaginable just a few years ago, when the challenge of gathering extensive user preference data seemed insurmountable. Today, however, we can develop a high-quality solution with only a small amount of seed data, which showcases what small teams like ours can now achieve.
For larger scale examples, see this post from Meta about Instagram’s recommendation system, and this one from Amazon about information retrieval.
We're also fine-tuning models to self-host, to give ourselves more flexibility in terms of capacity.
 |
|