

The LoCoMo "Fair Fight"
Is it still worth bragging when someone just claimed they hit 100%?


TL;DR:
At Continua, we are building long-term memory for multi-user AI, focusing on complex conversational context.
We tested our architecture on LoCoMo using an apples-to-apples comparison by adopting Mem0’s exact parameters.
We achieved an overall score of 74.4%, with strong performance in multi-hop reasoning at 78.8%, a 27-32pp advantage over peers using the same configuration.
Why another LoCoMo post?
When MemPalace open-sourced their memory system a couple days ago with a claimed 100% on LoCoMo, it went viral immediately. Within 24 hours, a Reddit thread had done the autopsy: the score was achieved by hardcoding fixes for known failures and several features marketed simply don't exist anywhere in the code. But MemPalace isn't really the point. By now, publishing a LoCoMo post is practically a rite of passage for building memory: Mem0 started the party in 60s, others fought back in the 70s and 80s (Zep, Letta, Memobase), and now scores are soaring into the 90s (MemMachine, EverOS), and apparently beyond.
We read all of them. And one thing kept bugging us: Companies are not playing by the same rules.
The headline numbers vary wildly, from ~65% to 100%, but each team uses different response-generation prompts, different answer models, different judge models, sometimes different judge prompts entirely. The “overall score” ends up being a function of the eval harness as much as the memory system. How much of that 35pp gap can be attributed to differences in memory architecture versus changes in the model and prompting?
We don’t know, so we decided to get a little obsessive-compulsive and run an apples-to-apples, same-model-same-prompt, no-shortcuts showdown.
Our Engine: A Knowledge Graph of Atomic Claims
Before we dive into the numbers, it’s helpful to understand the engine behind them. Continua’s memory stores conversations as a knowledge graph of atomic claims (for example, single facts like “Jordan’s birthday is March 22”), which are linked through entity nodes and typed edges.
When a question arrives, graph expansion walks those edges to surface related claims across 1-2 hops, and a hybrid ranker blends keyword and semantic signals to pick the best ones within a token budget. Over time, claims that get retrieved together develop stronger associations through a Hebbian “fire together, wire together” mechanism. This means retrieval improves with real usage, which remains largely unique in today’s market. (We will cover the architecture in detail in another post, as getting this right was far from obvious.)
Our approach: control everything, change only the memory
We didn’t choose our parameters to maximize our score; we chose them to match one of the earliest efforts to kick off benchmarking in this space: Mem0. Our goal is to strip away the noise and measure pure architectural performance by using the exact configuration as Mem0.
Answer/Judge model: GPT-4o-mini
Temperature: 0
Max output tokens: 8,192
Thinking tokens: Default
Response/Judge prompt: Mem0’s exact prompt
Categories: 1-4 (excluding cat 5 because no ground truth exists)
Questions: 1,540
Retrieval embedding model: OpenAI text-embedding-3-small
Results
Under the identical baseline conditions (Mem0’s exact same prompts and models) Continua hit 74.4%. This represents a ~7.5pp lead over Mem0’s published 66.9%.
Per-category breakdown
We report results against systems using the same answer model (gpt-4o-mini), same response prompt (≤5-6 words), and same judge prompt, making this a controlled comparison:
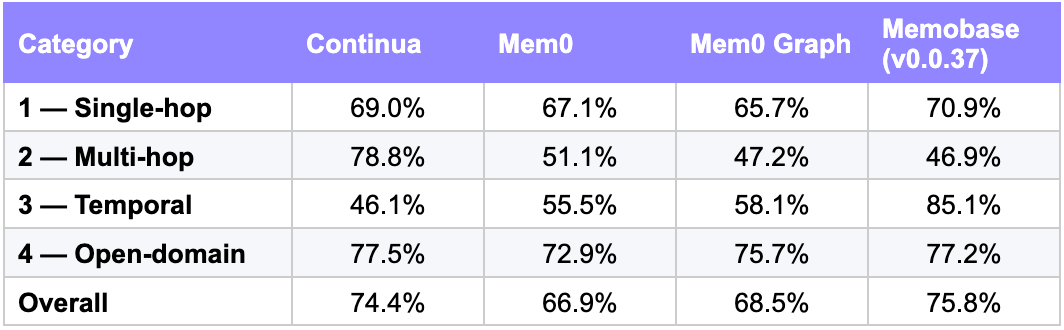
The per-category breakdown highlights where different architectures currently excel and where there is room for further optimization.
Multi-hop Reasoning: Our strongest area. At 78.8%, we lead by 27–32pp, driven by entity-based graph expansion that links related facts across conversations.
Temporal Reasoning: Our biggest gap. At 46.1% (vs. 85.1% for Memobase), we capture what happened well but lack explicit timeline reasoning. This is an area for us to improve.
Single-hop & Open-domain: Performance is similar across systems, with scores clustered in the high 60s to high 70s.
What these numbers don’t tell you
We want to be straightforward about what this evaluation does and doesn’t prove.
LoCoMo conversations are short. At 16-26K tokens each, they fit in modern context windows. As Letta and Zep have both noted, this means a “no memory” baseline is competitive at ~73%. LoCoMo really tests whether your memory system can achieve that same quality while being significantly more token-efficient than raw context dumping.
The gold answers are not perfect. A recent audit shared on Reddit revealed that 6.4% of the benchmark’s answer key is fundamentally flawed. Our verification confirmed these inconsistencies.
The judge is generous. Mem0’s LoCoMo judge prompt says: “you should be generous with your grading — as long as [the generated answer] touches on the same topic as the gold answer, it should be counted as CORRECT.” Under a stricter rubric, all published numbers, including ours, would likely shift, and the relative rankings might shift too.
We use GPT-4o-mini for the controlled comparison. This is deliberate: it matches Mem0’s setup. In a preliminary run with GPT-4.1-mini as the answer model (same retrieved context, same judge), Continua’s accuracy jumps to 84.5%, a 10pp lift from the model upgrade alone. This underscores how much published LoCoMo scores depend on model choice, and why controlled comparisons matter.
Summary
We are building memory for the complexity of multi-user AI, where conversations aren’t just linear 1-on-1 chats but interconnected webs of context. By running this “Fair Fight” with strictly controlled parameters, we’ve demonstrated a 74.4% overall score, with strong performance in multi-hop reasoning that our architectural design makes possible. We are also equally clear-eyed about our current limitations in temporal reasoning.
We’ll continue to evaluate our system with the same rigor against more benchmarks: strictly controlled, no “magic” shortcuts, and entirely transparent about where we’re crushing it and where we’re still just a “work in progress.”
 | A guest post by
|