

RAG In the Group Chat
How Continua Remembers What Matters Most


In case you haven’t heard, we’re agentifying the group chat! Our goal is to make the world’s best social AI, and that inevitably requires wrangling LLMs. In this post, I’ll be diving into one of the core features of our product that enables Continua to maintain social connections and remember what matters most to each user.
Now, LLMs may seem smart, but they know only as much as the content they are trained on. A model trained in 2024 cannot possibly know about the state of the world in 2025. For example, a medical chatbot built on a model trained in 2024 cannot provide updated vaccine schedules from experts in 2025. One way to address this issue is through Retrieval Augmented Generation (RAG), which allows LLMs to retrieve information from external data sources to provide up-to-date or domain-specific information. The retrieved content is provided to the LLM at the same time that it receives a user’s query, so that the content is in context and takes precedence over the information latent in the model’s parameters. Today, RAG is standard in systems built on top of LLMs.
RAG can be as simple or complex as you want it to be. In the simplest implementation, first, the information to be retrieved must be transformed into high-dimensional vector embeddings and stored. The embeddings are engineered to capture the semantic meaning of the information, so that items discussing similar topics will be stored closer to one another in the embedding space. (If that still doesn’t make sense, feel free to start a chat with Continua to ask about unfamiliar terminology. 😉) Next, during retrieval, the user’s query (message, input, etc.) will be embedded as well, and the most “similar” embeddings to the user query are retrieved, where similarity can be a combination of any number of metrics like cosine similarity or semantic similarity. RAG can optionally be extended further through methods like query expansion, where additional queries can be generated from the user’s original request, or through reranking, where the retrieved content is re-scored and pruned before being shown to the LLM.
NOTE: It’s important to recognize that RAG is not faultless. Providing an LLM with relevant context doesn’t necessarily mean that it interprets it the correct way. My favorite example of this is back from when we were creating personalized podcasts (see [1], [2], [3], [4], [5] if you’re curious). I had made a podcast about the Department of Government Efficiency (DOGE) and provided the LLM with a handful of news articles. On more than one occasion, the produced podcast would state that the content was completely made up and talked about a fictional department based on Elon Musk’s meme-coin. That’s because the LLM had been trained before Musk was appointed head of a newly created government agency. The only DOGE the LLM “knew” about was the crypto-currency. It didn’t matter that the system prompt told the LLM to consider the provided documents ground truth or that the documents were dated recently. To the LLM, today’s date is the one when it was trained, and no amount of prompting or context injection can convince it that it’s not acting in a “simulation.” The best we can do is prompt the LLM not to share its skepticism.
Potential pitfalls aside, RAG is still the industry standard for creating more grounded, intelligent, and current experiences. But what purpose does RAG serve for Continua’s domain-agnostic group chat agent? We address out-of-date information through web-search integration and we don’t necessarily need the agent to be an expert in any particular domain. We do, however, want our agent to maintain knowledge over long periods of time and across conversations.
For example, let’s say I’m in a group chat with three other friends, and in it we share our favorite restaurants.
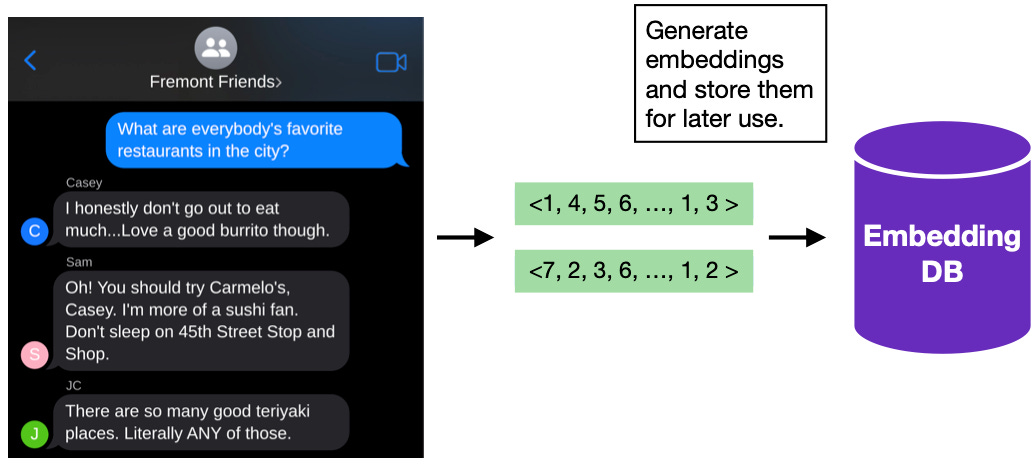
Later, I make a chat with two of those friends to plan a surprise party for the third. I want my agent to recall the preferences my third friend shared in the larger chat to best make recommendations for the surprise party. This is possible with RAG.
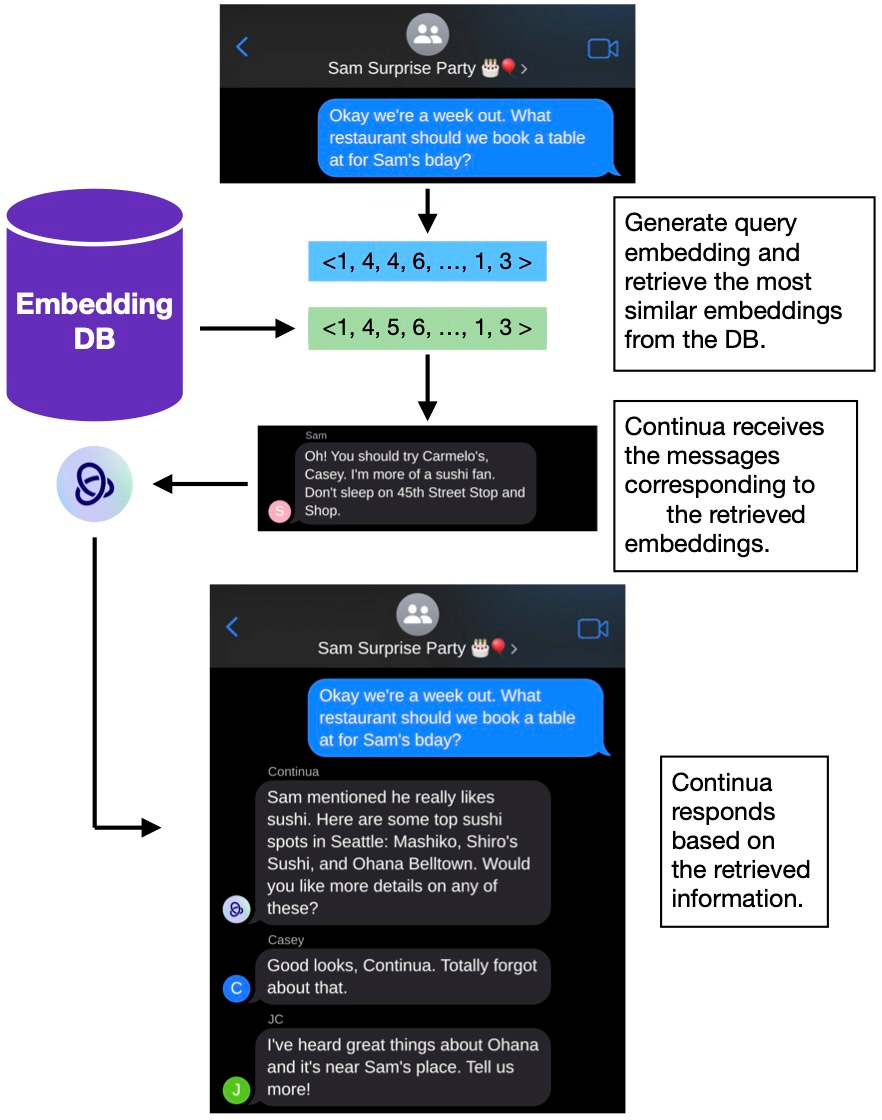
As you can see, RAG enables our users to have much richer conversational experiences. No more toggling between message threads or searching for keywords. Continua streamlines the experience. Great in theory! But in practice, there are many considerations to take into account when building our RAG system. Here are some of the questions we had to answer when building out each part of our pipeline.
Generating Embeddings
Are we going to embed each message individually or will we implement a chunking strategy?
If we’re chunking messages to embed, will we do so based on timestamps, topic changes, number of messages, or number of characters? Will there be overlap between chunks?
Are we going to embed messages in real time to make information immediately available or will we do it as a batch job later, potentially decreasing costs, but delaying information availability?
Do we embed the raw messages or do we pre-process them in some way? Do we need to have a decontextualization strategy?
The User Query
What is our user query? Is it one message or a chunk?
Do we treat each incoming message as a potential query or do we intelligently decide whether or not retrieval is necessary to respond to the user?
Should we expand the user query in order to get as much relevant information as possible? How?
Retrieving Content
How do we respect user privacy during retrieval, particularly when retrieving information from group chats?
How do we define similarity between embeddings? Messages are encrypted, so we can’t rely on semantic clues.
How do we decide that an embedding is “similar enough” to retrieve? Do we threshold on a similarity score? How do we ensure this threshold is meaningful? Does it need to be updated regularly?
How do we ensure retrieval is efficient and scales with the number of users?
Providing Retrieved Content to the LLM
Once we retrieve content, do we show all of it to the LLM or do we cherry pick?
Do we need to have a re-ranking strategy post retrieval?
Does adding complexity to the RAG pipeline increase latency too much? How do we ensure Continua responds in “real-time”?
Eval
How can I tell if the RAG pipeline is working as intended?
Are we actually retrieving relevant content? We don't see user messages, so we don’t know if users are satisfied with Continua’s responses.
Building this system required careful consideration at every step and each decision came with various tradeoffs. We could probably write a separate blog post for each one, but for the sake of maximizing time spent engineering vs blogging, we won’t be doing that. Besides, we're growing our ML team and these might be interview questions! Jokes aside, to this day, we’re tinkering with various pieces of the pipeline to create the smoothest, most intelligent system possible. We hope you try it out and let us know what you think!
 | A guest post by
|