

Engineering in the Age of Agents
Lessons from Letting AI Write Our Code



As an engineer, I think it’s important to acknowledge the rapid pace of change that has hit the industry as a whole these last few months. At this time last year, I wrote most of the code myself and sporadically turned to Claude when I got stuck. Today, to quote our CEO David, AI has become our “thought partner.” We went from driving the AI to letting it take the wheels and guiding it.
At Continua, our team spans the entire spectrum of vibe coding sceptic to power user. Some of us believe human eyes should never have to read another line of code, while others want visibility into every decision made by the agent. We’ve settled on an approach somewhere in the middle, but every single engineer is pushing the limits of the tools available.
Late January, our usage hit such a peak that we had to appoint an “AI Coding Tools Captain” to manage spend and align procedures. The following post outlines how we’ve adopted agentic development as a company and some of the lessons we’ve learned along the way.
Agent-Driven Workflows
After trying what feels like every coding agent out there (Claude Code, Codex, Warp, etc.), as a team, we’ve decided to build on top of pi, a “minimal terminal coding harness.” Pi lets you interface with any LLM provider, define skills, and store context for better utility.
To quote our captain, “Pi is to other coding tools as Linux is to other OSs.” A cool thing about Pi is that it’s open source and maintained by “just another guy” (a very, very impressive guy, but just a guy nonetheless). That means that if you want to make a PR to improve the tool or make a comment about an existing feature, you can directly interface with him, not tech support at a frontier lab. The other nice thing for us being aligned as a team is that we can share Pi skills both internally and externally as open source contributions. Over the last two months, we’ve built out a handful of skills. I’ll quickly mention two of my favorites.
Subswitch
This skill lets Pi switch between any number of LLM API keys or subscriptions. It was born out of our realization that we were, candidly-speaking, burning money on tokens. We didn’t think that subscriptions could meet our needs, but turns out, they do! Subswitch lets you set up a hierarchy of LLM access points. Let’s say you’re using your OpenAI subscription, when you’re limited for the next 6 hours. For that time, Pi will automatically switch to using the next access point on your list, like your OpenAI API key, until the subscription is available again. What if you spend too much on the key and the 6 hours aren’t up yet? Then you’ll switch to your next-ranked choice, your Anthropic subscription, and so on.
Happy Paths
Every new coding session with an agent starts from a blank slate. If an agent hit an error in the last session and it happens to hit that error again in the current session, it doesn’t remember how it solved the issue previously. It will follow the same steps to resolve the error as it did before. The same failure pattern repeats at every scale. It starts with one engineer and one agent looping on avoidable dead-ends, then compounds when multiple agents run concurrently and replay each other’s mistakes. At team scale, engineers rediscover similar fixes independently and the cost becomes org-wide.
Happy paths instead remembers what worked and intervenes at the moment of failure, before the agent wastes time and tokens rediscovering the fix. It captures agent traces, indexes them, mines wrong-turn corrections, and feeds those recoveries back into future sessions. Think of it as a global-sharing skill-exchange. Below is an example of how Happy Paths appends a short recovery hint to an error output before an agent sees it.
Agent runs `pytest tests/` → error: “pytest: command not found”
↓
Happy Paths matches error pattern
↓
Appends: “This project needs setup. Create a venv,
install dev deps, check for setup scripts in the
repo root, then use .venv/bin/pytest.”
↓
Agent follows recipe → skips 3-4 wrong turnsLessons Learned
Of course, adopting an agent-driven workflow has come with a handful of lessons for the team. We’re a far cry from having it all figured out, but operating at the edge of innovation means we have valuable insight to share.
There’s a new pace of development.
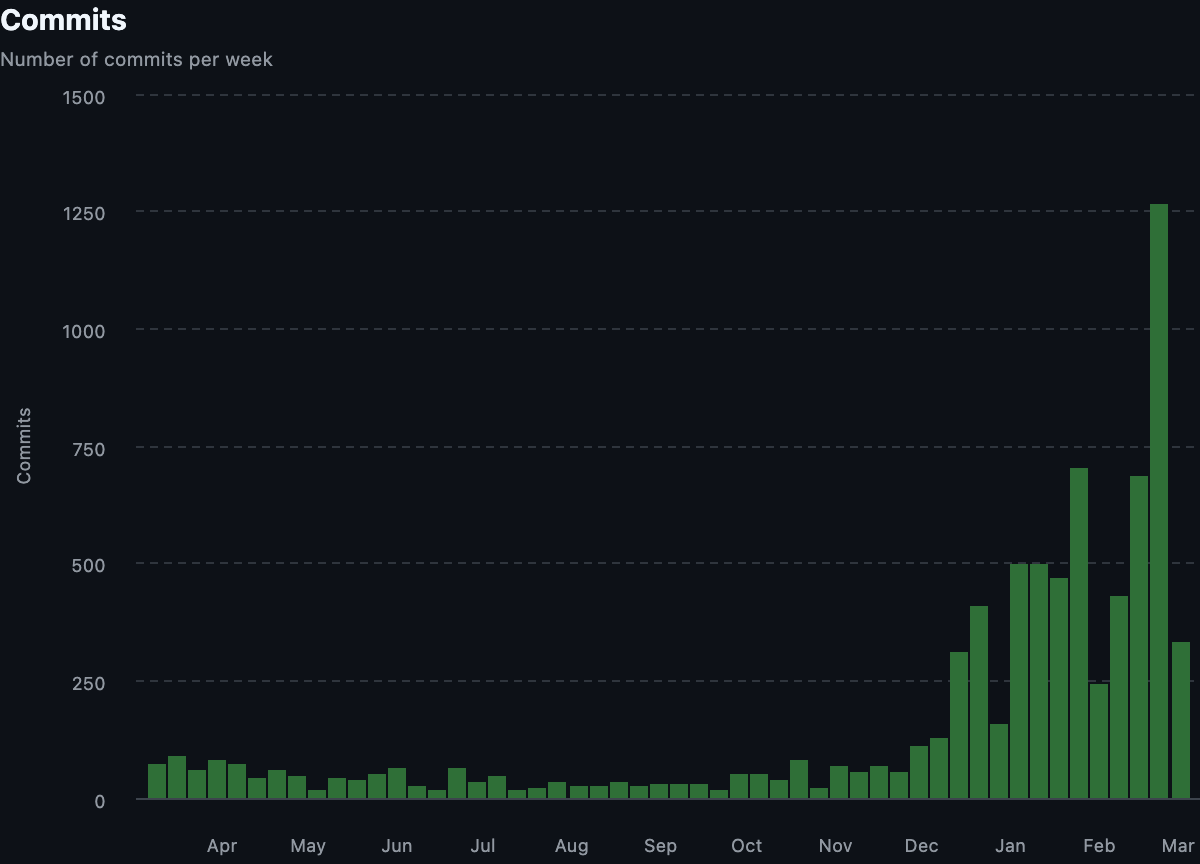
For the slower adoptees, there was a lot of frustration that came from trying to understand a codebase that felt like it was changing underneath you every day. Trying to debug why Continua isn’t responding, when the chat loop doesn’t look anything like it did earlier that week, feels impossible. The early adoptees argued we just had to use AI to understand the changes, and while there is validity to that stance, they also conceded that somebody should understand how the system functions in its current state.
Therefore, we hardened code ownership. If an engineer wants to change how a fundamental piece of the system operates, they MUST loop in the engineer that owns that piece and go through code review. At the same time, engineers have full reign to vibe away on the parts they own and may loop in others as they deem appropriate. They are also responsible for quickly identifying and addressing any bugs their code may introduce.
Humans are the bottleneck.
Agents unlock a pace of code production that is not humanly possible to keep up with. By iterating between a quality assurance and a builder agent, you can get a working product in a timespan unthinkable just months ago. The slower adoptees had to get more comfortable with ceding control to the agent. To resist was to kneecap our potential.
One side effect that we’re currently facing is that things break a lot more often. When you’re developing something individually, you have more leeway in what can go wrong. When you’re collaborating in a repository with other engineers, breaking internal tooling and infrastructure affects other people too. As a result, we need our automated testing to be airtight. We’re hardening our tests and also making sure that the agent has all the tools it needs to test itself. That brings me to the next lesson.
Every tool should have an API.
Earlier this year, our CEO, David, had an epiphany: if all the information employees at the company use to make decisions was available to an agent, it could ingest metrics, logs, conversational analysis, and propose product experiments, even orchestrate A/B testing. It would “close the loop.”
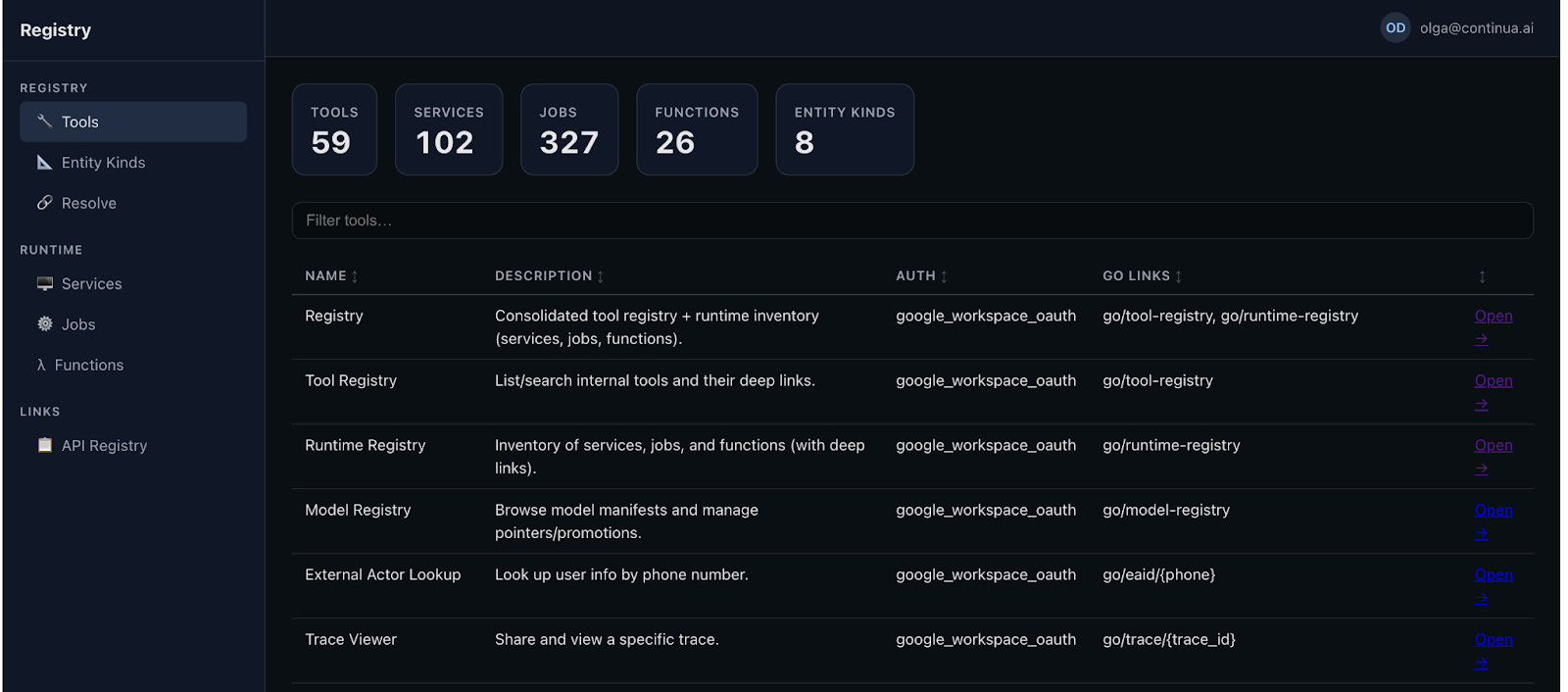
Our policy is simple. If you build an internal tool, you have to give the agent access to it. We’ve seen incredible productivity gains by doing so. Internally, we have an issue viewer that alerts us to strange conversational behavior, an eval runner that lets you test how your PR will affect system quality, a method for filing issues, etc. These now all have APIs exposed to the agent. That means an agent can autonomously scan for reported problems, make an issue about it in our tracking system, begin addressing the issue, make a PR for us to approve, and kick off an eval.
We don’t have to tell the agent which APIs to call. It has access to an internal registry that describes all the tools at its disposal and can make the right decisions on its own. There is immense power in letting the agent follow its own path to success, instead of forcing it to check in with you every step of the way.
It is possible to swing too far.
Some engineers joined the company just as we were ramping up our agentic usage. They quickly realized that while they were making measurable improvements to the product, they weren’t actually learning how the product operates. By virtue of not typing code in or looking at the lines being produced, they didn’t truly understand the system they were building on top of.
Our role as engineers is changing, but our core mission is the same: to deliver code that works. Using an agent does not absolve you from responsibility. I think part of the reason that people shy away from truly autonomous systems is that there isn’t somebody to blame. Consider when a Waymo ran over a beloved neighborhood cat in San Francisco. People were outraged. It didn’t matter that self-driving cars have a 90% crash reduction or 81% fewer injury-causing crashes compared to humans [source]. The fact is that if a human had hit the cat, they would have had to answer for it. Similarly, I believe that the role of software engineers is to shoulder the blame of our agents.
Whether it be through agentic feedback loops, manual review, or building better tests, the engineer manning the agent is the one who has to answer for and control its mistakes. The only way to prevent bugs is to understand what you’re building. This ethos has led to a swing back in the other direction. We still have agents write our code, but we’re a lot more disciplined about prompting them to explain their edits or prove their theses. We don’t blindly accept their edits.
AI is still wrong sometimes.
Let me repeat, AI is still wrong sometimes.
You should trust the human expert over the machine. Slop is still slop. An LLM is a non-deterministic, probabilistic machine. It is remarkably good at generating content and following patterns, but it does not understand, have a sense of ethics, or care about whether it is right. A model’s world knowledge is only as current as its training cutoff.
One of my favorite examples of the agent flubbing a task was when we were using it to debug an issue in our LLM calls. If you’ve used a newer Gemini model, you’ve heard of ‘thought signatures.’ These are encrypted bytes storing the internal reasoning of the model. During chat operations, they must be passed to the model according to a strict set of, admittedly confusing, rules. If you do not pass the signature correctly, your calls to the API will fail.
If you ask Gemini to debug how you’re using thought signatures, it gets it wrong. It genuinely isn’t up to date with its own documentation. You can give it a link to its own documentation, and it still can’t figure out a solution. You inevitably end up in one of those looping conversations where the agent says something along the lines of, “You’re right. That must be the issue.” as a response to whatever you say.
In this case, you should trust the engineer who spent a month digging into the problem over the agent. At the same time, it is that engineer’s responsibility to communicate the state of the problem. Most importantly, the engineer should share their knowledge with the agent via the AGENTS.md file, so that next time somebody is confused, the agent actually knows the right answer.
Our world is rapidly changing.
You can have positive, negative, or neutral feelings towards agent-driven development, but that doesn’t change the fact that the landscape is rapidly evolving. Staying up to date on the newest models and experimenting with how to utilize them best is essential. Can you believe we used to not have Copilot review every PR or that we used to manually update the code when a new model was released?! Our role as engineers is to adapt and build using the tools we’ve been given, and those tools are getting smarter and smarter.
Right now, engineers are the ones primarily at the forefront of agentic experimentation and development. At Continua, we’re building towards a future where all people, from all walks of life and backgrounds, have access to an agent operating on their behalf. While we can’t predict exactly what that will look like, we believe our products are a step in the right direction. Check us out and find out for yourself!
 | A guest post by
|