

Agentifying the Group Chat


In our last blog post, we announced that we’re adding AI to the group chat. We think the value proposition is obvious: seamless AI integration makes planning, coordination, and information retrieval in groups effortless. Honestly, the utility is so high, that you’d expect it to already be commonplace except for the fact that it’s actually pretty hard to get right. The reality is that today’s LLMs aren’t built for multi-user interactions. Their design is rigid, they only optimize to a single user, and they exist in their own realm of communication. At Continua, we’re tackling these challenges with a combination of different models, bespoke fine-tunes, and creative prompting. We even have several patents in the works for our more ambitious innovations. In this blog post, I’ll discuss the hurdles that make agentified group chats so difficult to achieve.
LLM APIs Aren’t Flexible
Today’s models are made for one-on-one conversations. The APIs have strict designs.
There is a single system prompt passed at the beginning of the conversation; there is no concept of a system message beyond this initial prompt.
The first message must be from the user, and there is only a single user identity. There is no way to define additional users.
The LLM operates in a call-and-response format, so that the agent always responds to the user’s message.
If you’ve ever talked to ChatGPT or Claude, you know that when you send a message, the model replies. This system makes sense in the context of DMs: you always expect the entity to which you’re speaking to respond. In fact, it would be disconcerting otherwise. When we switch to group chats, however, the existing paradigm no longer applies. First and foremost, there is suddenly more than one user present. Second, there may be entire conversations between subsets of users in the chat in which an agent shouldn’t respond, because it won’t provide any value. This setup creates three challenges:
1. Continua needs to know that it’s speaking to multiple people.
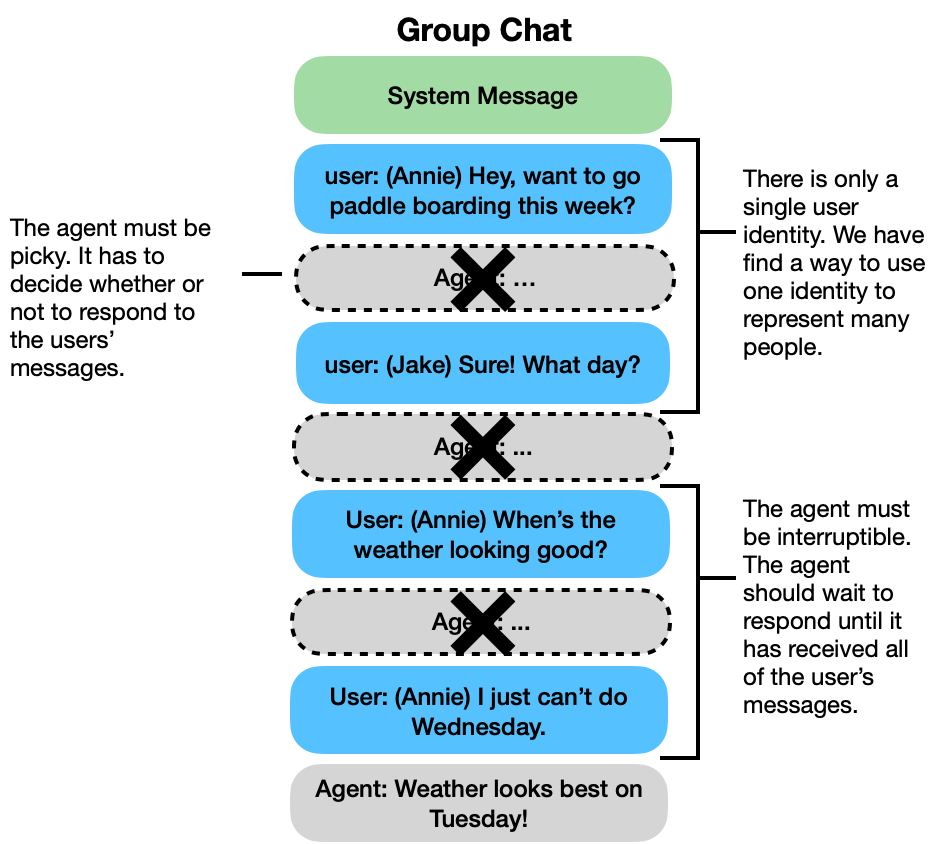
The problem is that from the viewpoint of the model, it is only ever speaking to one person. The API can only represent a single user identity. This means we have to find creative ways to represent many people through one identity.
2. Continua needs to be interruptible.
Continua needs to be able to consume messages continuously, and adapt its response to new inputs. For instance, if I send “Set a reminder to water the tomato plants every other day at 7 pm” and then my roommate immediately follows with “actually, make that 8 pm. We’re usually eating dinner at 7,” we need to interrupt Continua’s response to the first message, and instead respond to both. By doing so, we both prevent Continua from being too verbose and from sending potentially confusing messages to the users.
3. Continua needs to be “picky”.
Continua needs to look at every incoming message and decide whether or not it even warrants a response. The problem is that if you send an LLM a message, it will always respond. That means we have to be clever in the backend in deciding whether we show the user the response. Many cases are obvious (i.e., was Continua asked a direct question?), but most scenarios are not as clean cut. Consider the following: Annie, Jake, and Continua are in a group chat and Annie asks Jake if he wants to go paddle boarding. Should Continua immediately offer suggestions for where and when to go or wait until Jake responds? If Jake says yes and asks what day, should Continua proactively suggest the day with the best weather or should it wait to see if Annie has a day already in mind? Likely, the “correct” answer is different depending on the participants. Most current approaches to agentify the group chat get around the issue by only having the agent respond to messages with specific prefixes like “Agent,”, “+1”, or “/Agent”. The downside of this approach is that it means the agent is blind to any messages that weren’t addressed to it, leaving it with significant gaps in its knowledge of the conversation. At Continua, we let the agent see every single message, so that it has the full picture, and rely on our system to discern whether or not to respond. Yes, it’s more complicated, but it creates a much richer experience. Further, we ensure that Continua’s verbosity is tunable. We let our users instruct the agent to speak more or less depending on preference.
LLMs Only Adapt to a Single User
Another feature of today’s LLMs that doesn’t translate to group chats is that they are trained to optimize to a single user’s preferences. In a classic, one-on-one setting, the more you interact with an agent, the more it gets to know you and act in your best interest. But what does that mean in a group chat?
1. Whose interests take precedence in a group chat?
Should the agent act in the interest of the greater good, and if so, what is the greater good? These are philosophical questions, but they get at the fundamental question of what role AI should play in a group context. Should it serve as a mediator, take a neutral stance, and ensure that all parties feel heard? Or should it serve as a representative of a single user? We can consider examples for both scenarios. If a group of friends are planning a vacation together with Continua, no single user’s preferences should matter more than anybody else’s. If four people want to go camping and one wants to rent an RV, Continua should either suggest a compromise or plan for camping, since majority rules. If instead a public figure starts a chat with Continua and a student to coordinate a time to speak on a panel, Continua should prioritize the public figure’s availability and time constraints. At Continua, we aim to be at the forefront of designing a system that can accurately identify and address the needs of these scenarios.
2. What information is transferable from DM to group chat?
If users have built up a deep memory with their agent through DM, they may expect the agent to recall that information in group chats. The problem is that Continua doesn’t currently have a way of ensuring that information is “safe” to share. At the moment, we assume information shared in DMs is private. The only user information we pass from DM to group chat are settings a user has explicitly associated with their account, namely preferred name, location, and time zone. If a user tells us they want to be called “Sam,” we will respect that in every conversation. But if Sam tells Continua in a DM that they’re allergic to peanuts, and then Sam is added to a group chat with friends making dinner plans, Continua will not “remember” Sam’s allergy, because there’s no way for us to know whether Sam wants that information to be made public.
It’s Hard to Meet Users Where They Are
The last feature of LLMs I’ll discuss in this post that makes the transition from one-on-one conversation to group chats so difficult is platform. Most people interacting with LLMs today are doing so through a web UI or a bespoke app: places where the LLM’s “mannerisms” are already accepted. Users who seek out those services know what they’re signing up for. If instead, we want to meet users where they already exist in group chats: texts, Discord, Slack, Telegram, etc., we instead need to adopt the norms of those platforms.
1. The style of the agent’s response should depend on the platform where it exists.
It is well known that LLMs love to be verbose and instantaneously stream paragraphs upon paragraphs of information, but that’s not how real people communicate. A text is likely shorter than a discord message is definitely shorter than the default output of an LLM. Texts are sent in multiple, short chunks, while typed messages tend to be longer. Receiving a short message should be quicker than a long message, but delays of SMS/MMS are more common than delays in messages sent over WiFi. These features all need to be considered if you want to build an agent to whom speaking to feels natural, and what is natural in terms of timing, length, and formality will depend on context.
2. We need to be able to associate users across platforms.
A consequence of deciding to meet users where they are is that we need to know who they are in every setting. For instance, if the same set of users is talking to one another over discord and over text, Continua should be able to recall relevant details from either conversation. While the history of the conversations should remain separate, relevant information shared in either channel should be freely accessible. This is only possible if we maintain user identity across platforms.
Overall, it may seem like the odds are against us. We’re “jailbreaking” an existing system for our own goals, but the crazy thing is that it works. With some patent-pending innovation and creativity, we’re able to have truly transformative experiences in group chats that are indicative of a changing future and a changing norm of communication. If you’re excited to be at the forefront of that change, check us out at continua.ai. Add Continua to your group chat and see the magic yourself!
 | A guest post by
|